Este é o post gêmeo de O Pronunciamento de Michel Temer no Twitter. Agora, vamos analisar como foram as reações do público em sua página no Facebook. Para isso, raspamos todos os comentários em postagens da página do político do dia 16 ao dia 18 de maio usando o aplicativo Netvizz. Ao todo, foram seis postagens. Vejam o seu conteúdo:
library(tidyverse)
library(lubridate)
library(magrittr)
library(reshape2)
library(tm)
library(wordcloud)
setwd('~/Documentos/temer_facebook')
arqs <- list.files()
temer <- read_tsv(arqs[1])
stats <- read_tsv(arqs[3])
temer$post_text %>% unique %>% print
## [1] "O governo viveu nesta semana seu melhor e seu pior momento. Os indicadores de queda da inflação os números de retorno ao crescimento da economia e os dados de geração de empregos criaram esperança de dias melhores. Não podemos jogar no lixo da história tanto trabalho feito em prol do País. Não renunciarei. Sei o que fiz e sei da correção dos meus atos. Assista:"
## [2] "#AoVivo Acompanhe o pronunciamento do presidente Michel Temer:"
## [3] "Com as mudanças na gestão e o foco em produtividade a Petrobras voltou a crescer e dar lucro. Segundo o presidente da empresa Pedro Parente após um ano de governo do presidente Michel Temer a estatal reverteu prejuízos investiu mais e aumentou a produção. “É uma empresa que volta a ter condição de dar orgulho ao brasileiro”. Assista! Saiba mais: http://bit.ly/2r6uV3u"
## [4] "Para que a União seja forte é preciso que em primeiro lugar os municípios sejam fortalecidos afirmou o presidente Michel Temer em evento com prefeitos de todo o País. Temer reforçou o compromisso do governo em apoiar e dar autonomia às prefeituras para que voltem a investir. Contem com o governo disse. Saiba mais: http://bit.ly/2rn1Pdo"
## [5] "Com a retomada da economia o mercado de trabalho dá os primeiros sinais de recuperação. No mês passado mais de 59 mil vagas formais foram criadas sendo o primeiro resultado positivo para abril desde 2014. Os dados são do Cadastro Geral de Empregados e Desempregados (Caged) e foram divulgados nesta terça-feira (16) pelo Ministério do Trabalho."
## [6] "#AoVivo Presidente Michel Temer abre a 20ª edição da Marcha a Brasília em Defesa dos Municípios. Acompanhe: CNM - Confederação Nacional de Municípios"
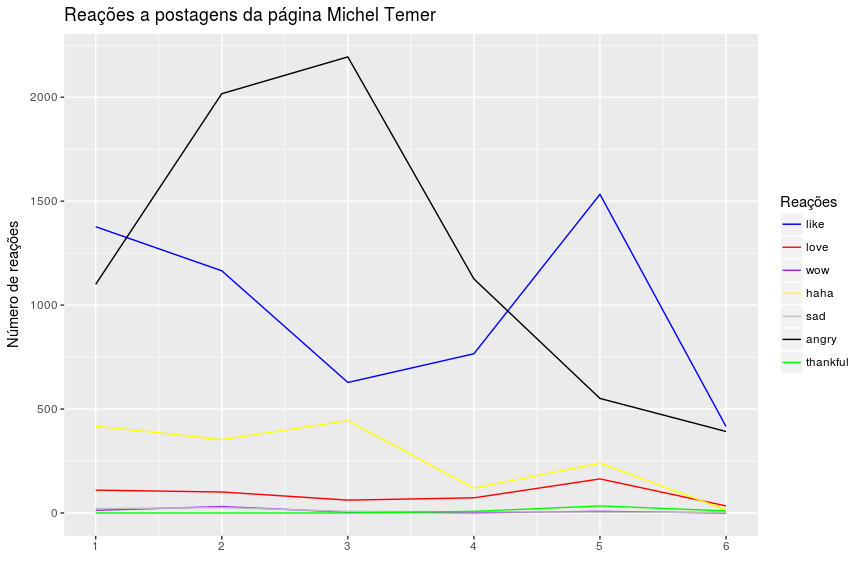
Agora vamos verificar como foram as reações a essas seis postagens.
like <- stats$rea_LIKE
love <- stats$rea_LOVE
wow <- stats$rea_WOW
haha <- stats$rea_HAHA
sad <- stats$rea_SAD
angry <- stats$rea_ANGRY
thankful <- stats$rea_THANKFUL
emotions <- data.frame(like=like, love=love, wow=wow,
haha=haha, sad=sad,angry=angry,thankful=thankful,
date=stats$post_published, id=1:length(like), stringsAsFactors = F)
mdf <- melt(emotions[,-8], id.vars="id", value.name="value", variable.name="reaction")
ggplot(mdf, aes(x=id, y=value, group = reaction, color = reaction))+geom_line()+
scale_color_manual(name="Reações",values = c("blue","red","purple","yellow","grey","black","green"))+
labs(title="Reações a postagens da página Michel Temer", y="Número de reações", x="")+
scale_x_continuous(breaks = c(1,2,3,4,5,6), labels=c(1,2,3,4,5,6))
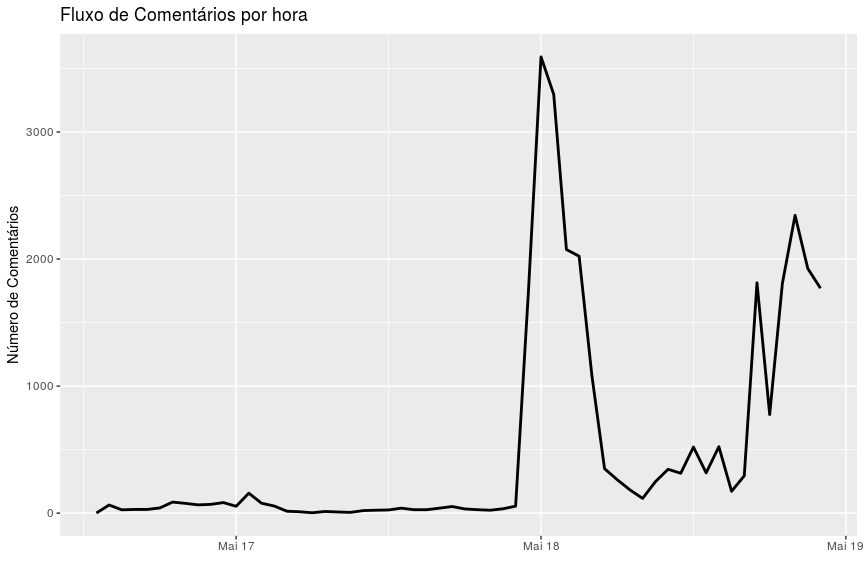
Agora, vamos olhar como foi o fluxo de comentário por hora na página.
temer$comment_date <- ymd_hms(temer$comment_published)
temer$comment_date <- round_date(temer$comment_date, "hour")
datas = as.data.frame(table(temer$comment_date), stringsAsFactors = F)
ggplot(temer, aes(x=comment_date))+geom_path(stat = "count", lwd=1)+
labs(x='',y='Número de Comentários', title="Fluxo de Comentários por hora")
Finalmente, vamos verificar as palavras mais usadas nos comentários.
text = temer$comment_message %>% tolower %>% removePunctuation %>% removeWords(., stopwords('pt'))
pal <- brewer.pal(9, "RdBu")[1:4]
wordcloud(enc2native(text), min.freq = 2, max.words = 100, random.order = F, colors = pal)

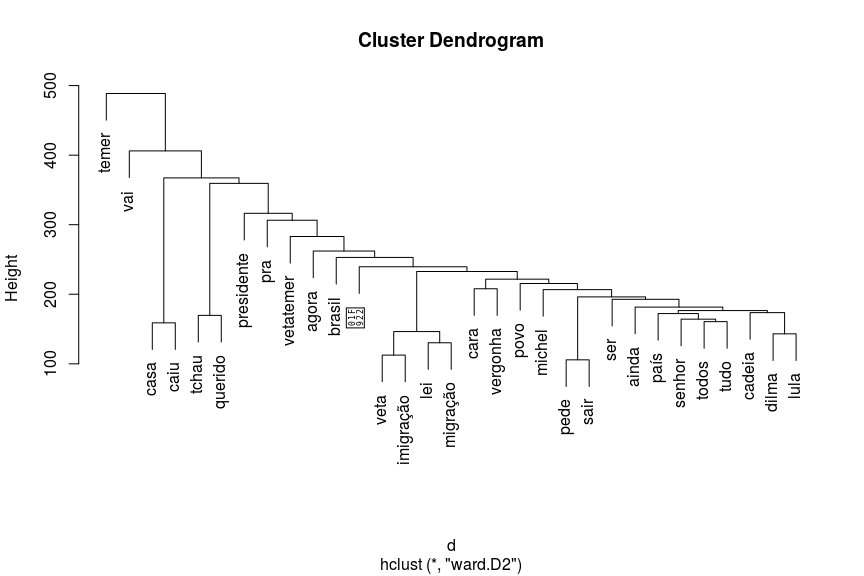
Agora, vamos verificar a emergência de assuntos através de clusterização hierárquica e através de uma rede de palavras.
corpus <- Corpus(VectorSource(text))
tdm <- TermDocumentMatrix(corpus)
tdm <- removeSparseTerms(tdm, sparse = 0.996)
df <- as.data.frame(as.matrix(tdm))
#dim(df)
df.scale <- scale(df)
d <- dist(df.scale, method = "euclidean")
fit.ward2 <- hclust(d, method = "ward.D2")
plot(fit.ward2)
library(igraph)
g <- graph_from_incidence_matrix(as.matrix(tdm))
p = bipartite_projection(g, which = "FALSE")
V(p)$shape = "none"
deg = degree(p)
#Retirando um emoji
p = delete_vertices(p,13)
plot(p, vertex.label.cex=deg/20, edge.width=(E(p)$weight)/100,
edge.color=adjustcolor("grey60", .5),
vertex.label.color=adjustcolor("red", .7))

Veja como os assuntos emergem no grafo. Comentários relacionados à proposta de lei de migração, jargões como “tchau querido” e a “casa caiu” e algumas palavras que saltam aos olhos como “vergonha” e “cadeia”.
Por hoje é só! Até a próxima!