Olá pessoal. Recentemente publiquei em meus perfis no Facebook e no Twitter algumas análises dos tweets publicados com a hashtag #QuedaDoPlanalto a qual esteve em primeiro lugar mundial e nacional durante o período conturbado da nomeação do ex-presidente Luíz Inácio Lula da Silva a Ministro da Casa Civil. Este assunto já está sendo amplamente divulgado e acredito ser absolutamente prescindível discutí-lo aqui. Me limitarei a apresentar os códigos usados para realizar a referida análise.
Primeiro, carregamos os pacotes necessários:
library(twitteR)
library(wordcloud)
library(tm)
library(plyr)
É necessário que você tenha uma conta no Twitter como desenvolvedor. Se ainda não possui, consulte este tutorial. Você precisará de quatro chaves: 1) sua consumer key, 2) sua consumer secret, 3) seu access token e 4) seu access secret. Para facilitar a digitação, guarde-os em objetos da seguinte forma:
consumer_key <- "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX"
consumer_secret <- "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX"
access_token <- "XXXXXXXXXXX-XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX"
access_secret <- "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX"
Para estabelecer uma conexão com o Rest API do Twitter, use:
setup_twitter_oauth(consumer_key,
consumer_secret,
access_token,
access_secret)
Agora, vamos começar a busca. Faremos uma requisição ao API do Twitter por 10.000 tweets que contenham #quedadoplanalto.
tweets <- searchTwitter("#quedadoplanalto", n=10000)
Em seguida, guardaremos os tweets baixados num banco de dados e o salvaremos em um arquivo .csv. Acho essa ação absolutamente importante para que seja possível a replicação das análises. Para usar o código abaixo, substitua […] pelo caminho da pasta onde você deseja salvar o arquivo.
bd <- ldply(tweets, function(t) t$toDataFrame() )
write.table(bd, "C:/.../tweets.csv",
sep = ";")
Agora, vamos começar a análise. Os tweets fornecidos pelo API vem em formato JSON. Para a análise textual, vamos extrair apenas o texto dos tweets e transformá-lo num corpus de análise no modelo do pacote tm.
text <- sapply(tweets, function(x) x$getText())
corpus <- Corpus(VectorSource(text))
corpus <- Corpus(VectorSource(tweets))
Agora, vamos limpar os textos. Primeiro, como os tweets estarão em português, vamos convertê-lo para o formato “latin1” que aceita acentos para que não haja desconfigurações. Depois vamos colocar todo o texto em letras minúsculas, remover a pontuação e retirar algumas palavras que não são úteis para a análise como preposições, etc (stopwords).
(f <- content_transformer(function(x) iconv(x, to='latin1', sub='byte')))
corpus <- tm_map(corpus, f)
corpus <- tm_map(corpus, content_transformer(tolower))
corpus <- tm_map(corpus, removePunctuation)
corpus <- tm_map(corpus, function(x)removeWords(x,stopwords("pt")))
Agora, vamos montar uma núvem de palavras com no máximo 100 palavras. Se montarmos uma núvem com palavras demais, a máquina pode não responder de forma satisfatória além de obtermos uma figura ininteligível. Para isso, use o comando
wordcloud(corpus, min.freq = 2, max.words = 100, random.order = F)

Para salientar as palavras por frequência use
library(RColorBrewer)
pal2 <- brewer.pal(8,"Dark2")
wordcloud(corpus, min.freq=2,max.words=100, random.order=F, colors=pal2)
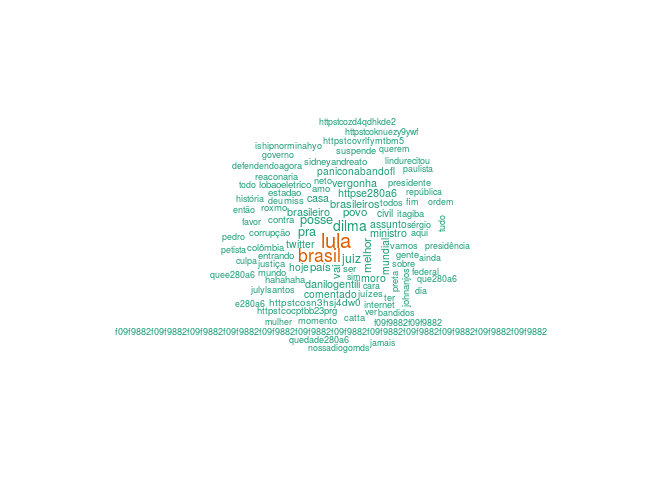
Para a análise classificatória, precisamos montar a matriz Termos-Documentos. Para isso use o comando
tdm <- TermDocumentMatrix(corpus)
Depois disso, vamos retirar as palavras esparsas, e transformar a matriz num banco de dados. É bom olharmos as dimensões do banco de dados para sabermos quantas palavras iremos efetivamente analisar.
tdm <- removeSparseTerms(tdm, sparse = 0.98)
df <- as.data.frame(inspect(tdm))
dim(df)
## [1] 53 9993
Depois disso, calcularemos a distância euclidiana entre as palavras.
df.scale <- scale(df)
d <- dist(df.scale, method = "euclidean")
Por fim, pedidmos uma clusterização hierárquica pelo método da variância mínima de Ward e a plotamos.
fit.ward2 <- hclust(d, method = "ward.D2")
plot(fit.ward2)
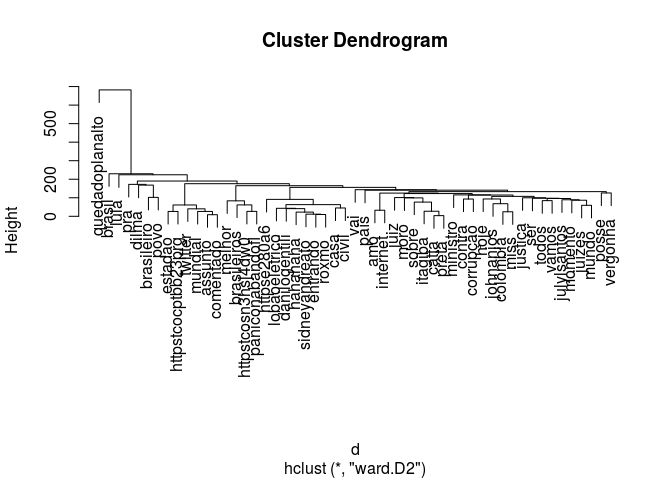
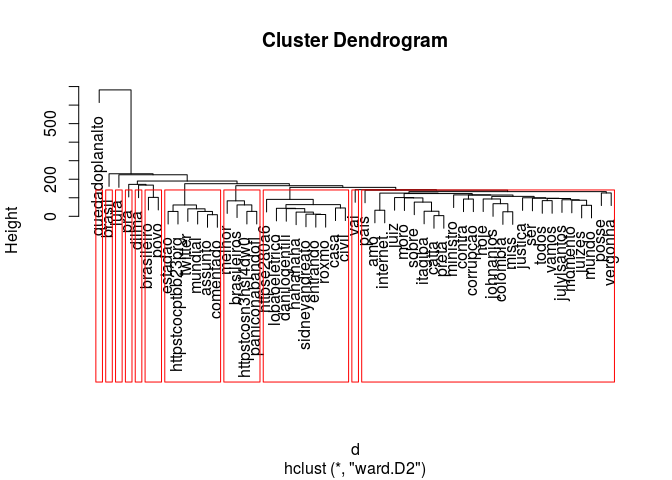
Para facilitar a visualização dos grupos formados usamos o comando rect.hclust:
plot(fit.ward2)
rect.hclust(fit.ward2, k=11)
Espero que o post seja útil. Se tiverem dúvidas, críticas ou elogios, por favor comentem no post. Um grande abraço.